|
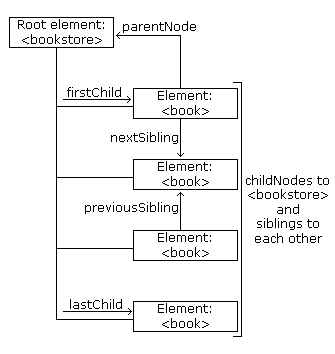
Die Funktion im Beispiel oben �berpr�fen die Nodeart des ersten Kind Nodess.
Element Nodes hat nodeType von 1, also, wenn der erste Kind Node nicht ein Element Node ist, bewegt er auf den folgenden Node und �berpr�ft, ob dieser Node ein Element Node ist. Dieses f�hrt fort, bis der erste Kind Node gefunden ist. Auf diese Weise, das Resultat ist in Mozilla und im Internet Explorer korrekt.
|